AI-powered visualization
& alerts
Send any output from your jobs - raw log text, JSON payloads, SMART reports, backup stats. The AI pipeline reads it, recognises what's worth tracking, suggests which metrics to chart and what to alert on, then builds the dashboards automatically.
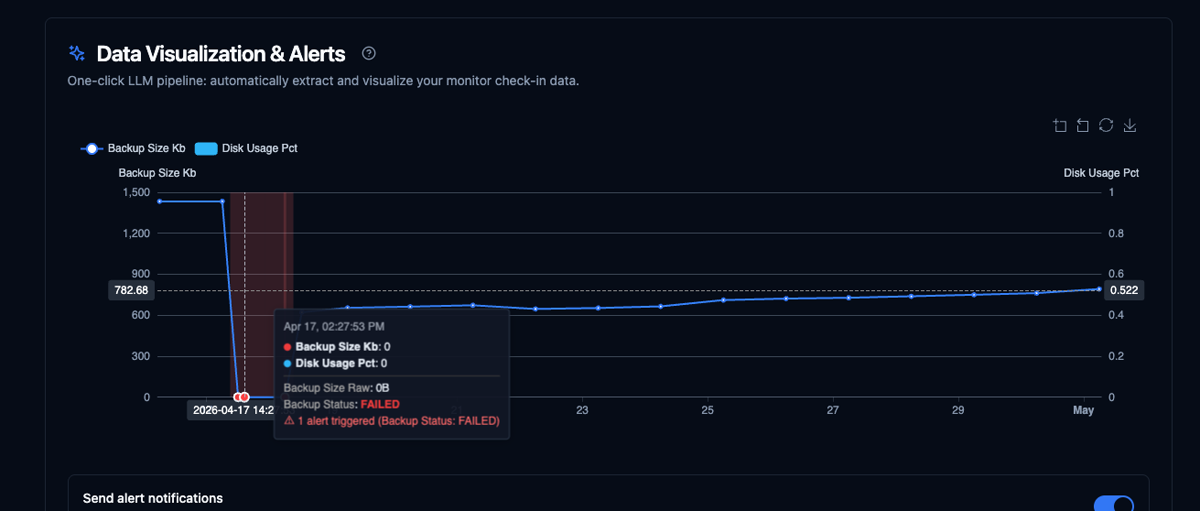
Alert detection
Catch failures before
they cost you
AI analyzes check-in payloads, generates alert rules automatically, and annotates the exact data point where things went wrong - like a backup dropping to 0 bytes.
- LLM-generated alert rules from your data shape
- Instant notification on threshold breach
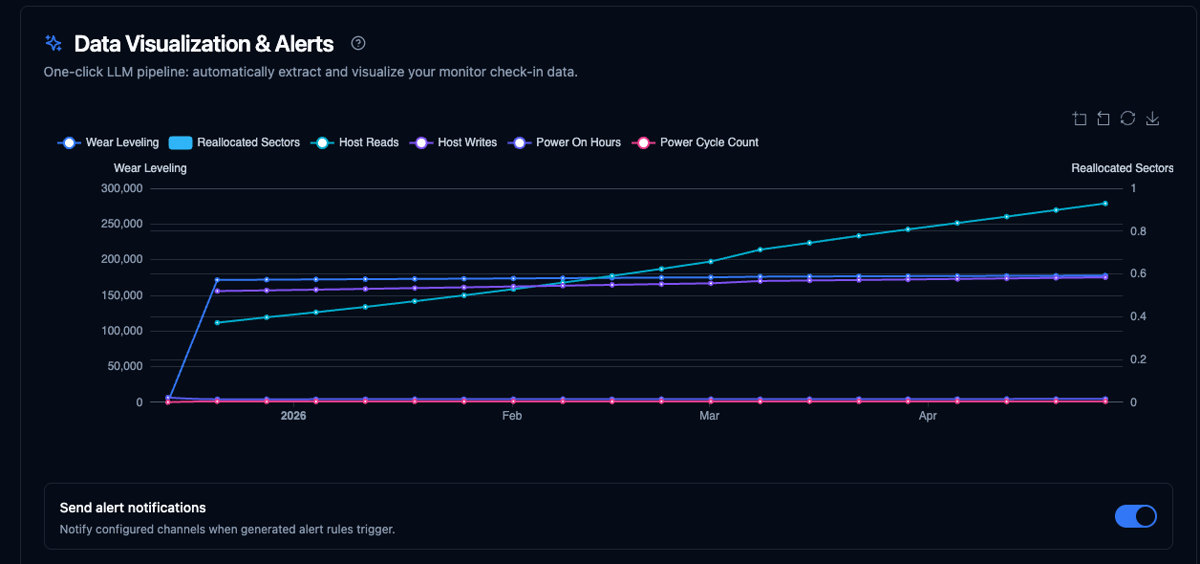
Auto-charting
Any structured data,
instantly charted
Works on any output - structured JSON, plain log text, SMART reports, even free-form prose. The AI reads the content, identifies the meaningful signals, recommends which fields to chart and which thresholds to watch, then renders the dashboard in seconds.
- Structured JSON and unstructured text - no schema required
- AI recommends metrics to track and thresholds to alert on
- Multiple metrics on one chart, dual axes
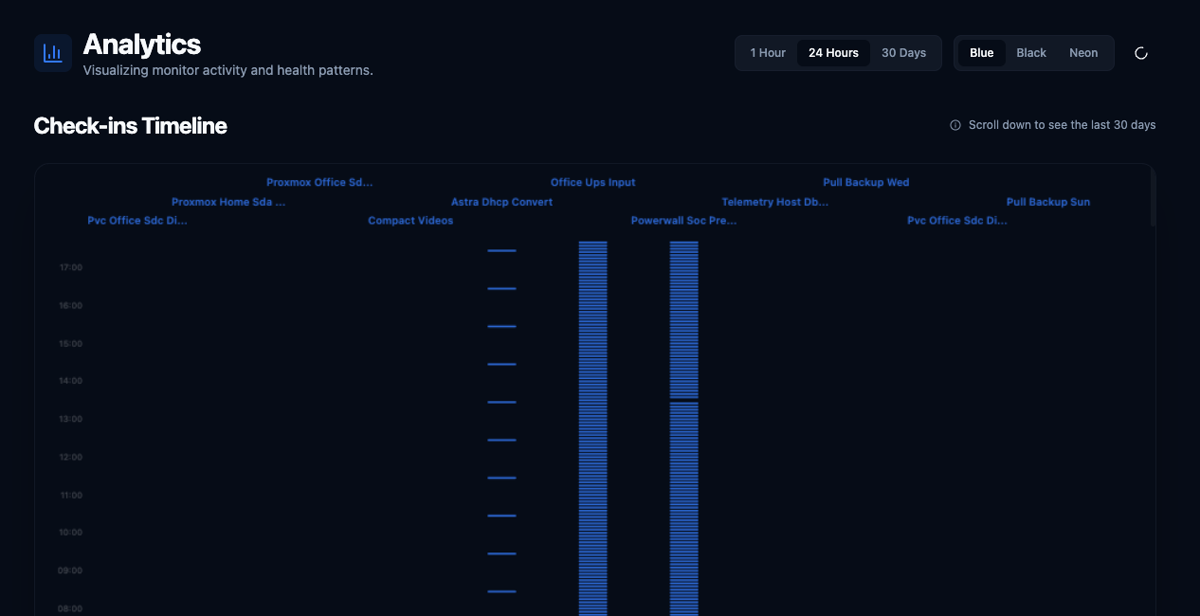
Analytics
See your entire fleet
at a glance
The built-in analytics timeline plots every check-in across all your monitors on a single canvas. Spot gaps, burst patterns, and missed runs in seconds - no log digging required.
- 1-hour, 24-hour, and 30-day views
- Blue, Black, and Neon colour themes